(GSoC) Week-3 Entity Linking - Techniques used
Hello. In this blog, we will continue with entity linking(read previous blog for intro and simple demos), methods that I am using for entity linking in my project and some recent techniques that can be used to perform EL.
Background
In the previous blog, I had mentioned of using DBpedia lookup, DBpedia spotlight etc. In this blog, I will try to discuss how these work, discuss some approaches that I am using in my GSoC project to perform EL and also discuss some ideas like zero-shot classification that can be used to perform and enhance EL.
Some concepts (If already faimiliar with these, jump here)
Indexing - It is a data structure that is created to efficiently store and retrieve information from a collection of documents or data. The index allows for quick lookup and retrieval of documents based on user queries or search terms. Below are some indexing techniques:
- Inverted index - Simply put, an inverted index is a mapping from tokens/words to the documents/texts that contain them.
-
N-gram indexing - It is similar to inverted index, just that instead of using tokens, it splits the text into n-grams and adds them to the index along with the docIDs of the documents in which they appear.
-
Positional indexing - Along with the docIDs, this also stores the position of the token/n-gram in the each document where it appears, this helps in phrase and proximity searching.
As for textual search, indexing is also used to search for entities based on candidate entities. In this, we can think of documents as entities/resources in a knowledge base and the query as the candidate entities extracted from text, and we search for the resources that best link/match to these.
To get a more detailed idea(along with some code) about indexing, refer to my blog on indexing in IR.
Compression - Indexes can become memory intensive, especially for large document collections, so compression techniques like dictionary encoding(replacing unique index terms with integer identifiers), variable byte encoding, gap encoding, front codint etc. I will discuss in detail about these in some other blog post. For now, please refer to this.
DBpedia lookup:
It uses the Apache lucene index for resource indexing and retrieval. Lucene also uses an inverted index. It indexes documents over fields(like name of doc, author, abstract, date of pulication etc). The Lucene search API takes a search query and returns a set of documents ranked by relevancy with documents most similar to the query having the highest score.
A nice blog to learn concepts of lucene.
DBpedia spotlight:
In common text retrieval tasks, TF-IDF score is used to rank documents. For a document D, if the TF for a term t in the query is high, the document is more relevant to the query, and at same time, if the IDF for the same term t is high for the same document D, we say that the term is more specific to that document, thus increasing its relevance.
In entity linking tasks, where the query term is the entity mention in text( for example “England” in “England won the 2019 cricket world cup.”) and the candidate entities in the KB are like documents which we want to retrieve and rank, TF refers to relevance of a word in a resource. Despite its success in document retrieval, IDF gives the global importance of a word, but fails to capture its importance for a set of candidates. In order for words to be able to disambiguate candidate entities, DBpedia spotlight uses the Inverse Candidate Fequency(ICF) weight.
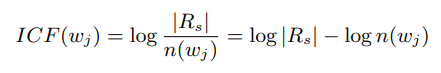
In the above ICF definition, Rs refers to set of all candidate entities/resources for surface form s. And n(wi) refers to number of resources in Rs that are associated with word wi.
More about spotlight(theory) can be found here.
My approach:
I had a few options like I mentioned previously, using DBpedia lookup or spotlight or some pre-populated databases containing entities and their surface forms. So, instead of using them individually, I thought of using all of these approaches and then using a majority vote on top. This was a natural choice as a result of my experience of seeing ensembles work well.
So, what I am doing is, getting top-2 or top-3 results from DBpedia lookup, spotlight and the database that I have, and then select the entity which has appeared majority of times.
I tried this approach on the following set of sentences, for demo.
sent1 = "Lionel Messi is a football player from Argentina"
sent2 = "Colorado is in USA"
sent3 = "Hitler was the ruler of Germany during World-War-2"In these sentences, I hand-picked the entities for the sake of testing my approach. So the entities that I identified are:
entities = [
"Lionel Messi", "Argentina",
"Colorado", "USA",
"Hitler", "Germany", "World-War-2"
]After using lookup and the redis database that I have, I could link 6 of the 7 entities to resources in dbpedia. And when I also combined results of spotlight, all 7 out of 7 entities could be linked to resources. This was a small experiment to assure that ensembles work well. The entities and linked resources:
{'Lionel Messi': 'http://dbpedia.org/resource/Lionel_Messi',
'Argentina': 'http://dbpedia.org/resource/Argentina',
'Colorado': 'http://dbpedia.org/resource/Colorado',
'USA': 'http://dbpedia.org/resource/United_States',
'Hitler': 'http://dbpedia.org/resource/Adolf_Hitler',
'World-War-2': 'http://dbpedia.org/resource/World_War_II'
'Germany': 'http://dbpedia.org/resource/Germany'
}
Though this was a simple example, I am exloring further how we can make use of the context around the entities to link to more contextually correct resources(planning to use zero-shot abilities of models here). That will be it for this blog.
Thank you!