Indexing in information retrieval
Hello. This blog is about indexing techniques used in information retrieval. I will try to cover some basic indexing techniques and also provide code for some of them.
What is indexing?
An index is a data structure that is created to efficiently store and retrieve information from a collection of documents or data. The index allows for quick lookup and retrieval of documents based on user queries or search terms. In search engines, web pages are indexed, when user enters a query, the engine finds the relevant documents quickly using the index. Below are some indexing techniques:
- Inverted index - Simply put, an inverted index is a mapping from tokens/words to the documents/texts that contain them. To create an inverted index, the document is pre-processed(stemming, normalization, stop-word removal etc), then tokenized, and then each term is added to the index along with the document IDs of documents in which it appears.
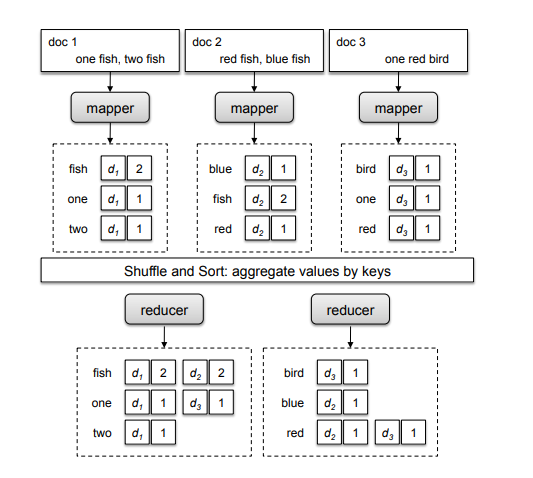
-
N-gram indexing - It is similar to inverted index, just that instead of using tokens, it splits the text into n-grams and adds them to the index along with the docIDs of the documents in which they appear.
-
Positional indexing - Along with the docIDs, this also stores the position of the token/n-gram in the each document where it appears, this helps in phrase and proximity searching.
Some basic code
I have referred to this site for the code, all credits to them.