(GSoC) Week-11, 12 and 13 Recent Updates
Hello. Its been a while since I have put an update on the project(travelling and network issues). I had been working on some polishing, enhancing and re-experimenting, with the models that we are using, the time it takes to process the inputs etc. In this blog, I will give a review of these.
Restating the Goal
Just to make sure we are clear about the end goal, given a wikipedia page(an entity), we need to disambiguate the predicates/relationships between the page and all other pages(other entities) that are linked from that page. More precisely, we want to find the relationships between those pages which are only connected by the dbo:wikiPageWikiLink predicate and no other predicate, or mine the text to see even a relationship exists or not. There are cases where some page is linked in references, but is not related to the wikipedia page. The goal is to find all those hidden relationships by processing the wiki page text.
Processing time for major components of pipeline
Fetching wiki page and getting pure text - On an average, it takes about 0.76 seconds to fetch a wikipedia page and extract pure text from it. Though this can be done in parallel for multiple pages.
| Method | 1 Page | 4 Pages | 20 Pages |
|---|---|---|---|
| Sequential | 0.76 seconds | 3.04 seconds | 11.09 seconds |
| Parallel | 0.76 seconds | 0.91 seconds | 3.05 seconds |
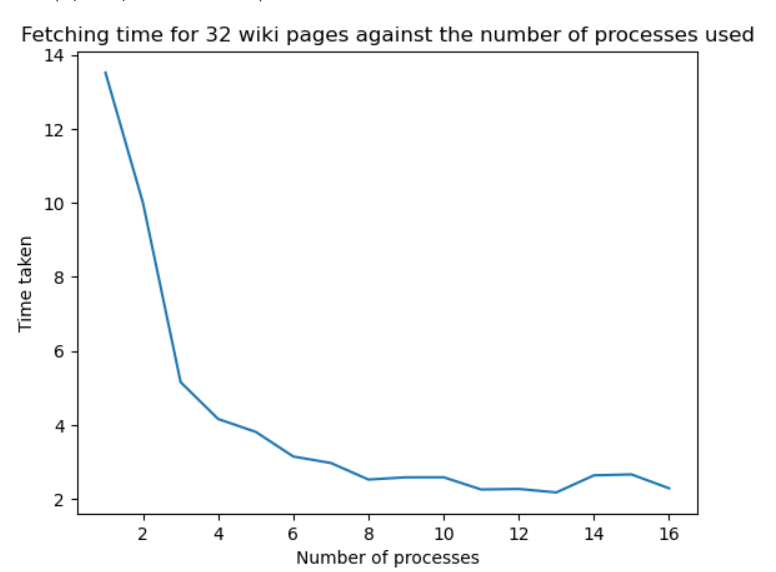
I tried experimenting using different number of processes to fetch 32 wiki pages, and below is the graph of the time taken in each case. (Time is in seconds)
Extracting entities and relations with REBEL - This is one of the most important parts of the pipeline. With a GPU enabled, following are the times takes by the model for extraction.
| Number of sentences(sequential) | Time taken |
|---|---|
| 10 | 6.1 seconds |
| 100 | 53.18 seconds |
On an average, it takes around 0.5-0.6 seconds per sentence.
Entity Linking using GENRE - This step links the entity mentions extracted by REBEL with DBpedia entities. On an average, GENRE model takes around 2.26 seconds to link one entity mention. This is probably the largest time consumer in the pipeline.
Update(5th Sept, 2023)
I tried making a small change in the way I am using GENRE, earlier we were doing this:
outputs = model.generate(
**tokenizer(annotated_sentences, return_tensors="pt", padding=True),
num_beams=5,
num_return_sequences=1,
)
entites = tokenizer.batch_decode(outputs, skip_special_tokens=True)
It was taking around 2.26 seconds per entity on an average.
Now I used transformers pipeline, and it improved the speed.
genre_pipe = pipeline(model="facebook/genre-linking-blink", tokenizer="facebook/genre-linking-blink")
entites = pipe(annotated_sentences)
And now we have around 0.65 seconds per entity on an average, so a 3.4 times performance improvement.
Relation mapping - This is the part where we map the textual relation with a DBpedia predicate based on the vector similarity score. This part works pretty fast with about 0.025 seconds per relation(so we can say per sentence).
End-2-End Extraction - This time this takes depends on the number of triples that are extracted from the sentence that is passed to this. If we consider around 5 triples per sentence(considering long sentences), it takes around 25 seconds on an average. This is justifiable as each triples has 2 entities and 1 predicate, so as per previous points, REBEL takes around 0.5 seconds, then we need around 2.26 x 2 = 4.52 seconds for entity linking. So, it adds up to about 5 seconds per triple.
Update(5th Sept, 2023)
After the performance improvements in GENRE, the new average time for end-2-end processing of each triple will be 0.5 seconds for REBEL, then 0.65 x 2 = 1.3 seconds for GENRE, so around 1.8 seconds per triple.
</span>
To understand the time taken for this end-2-end process, we need to get some insights into the lengths of the wikipedia texts, sentences etc. Below is a plot of the distribution of sentence lengths in terms of words(analysed over some wiki pages):
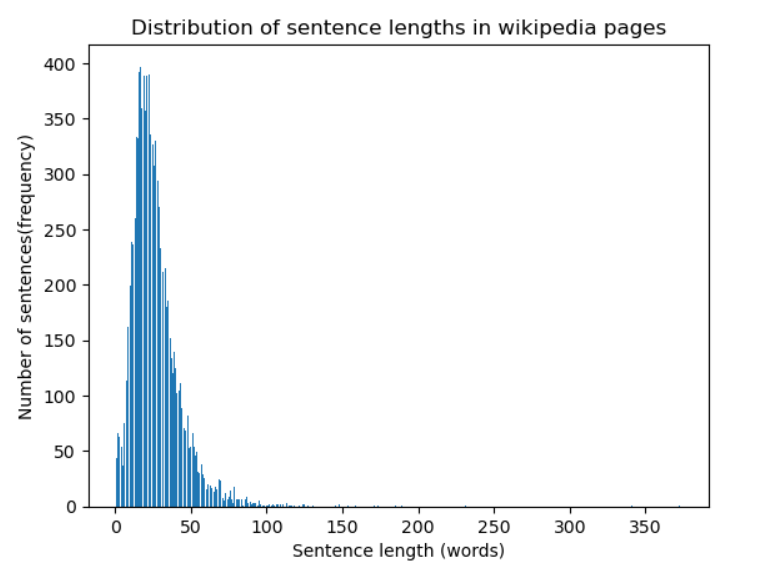 The mean length of a sentence is about
The mean length of a sentence is about 26 words. There is a high chance that such sentences contain more triples. And thus, more time to process.
Some new issues with REBEL
In one of the previous blogs, I had mentioned that REBEL goes wrong in case of factually correct sentences, but containing a negation. I found another issue with this model extracting wrong information.
For example, consider the image below:
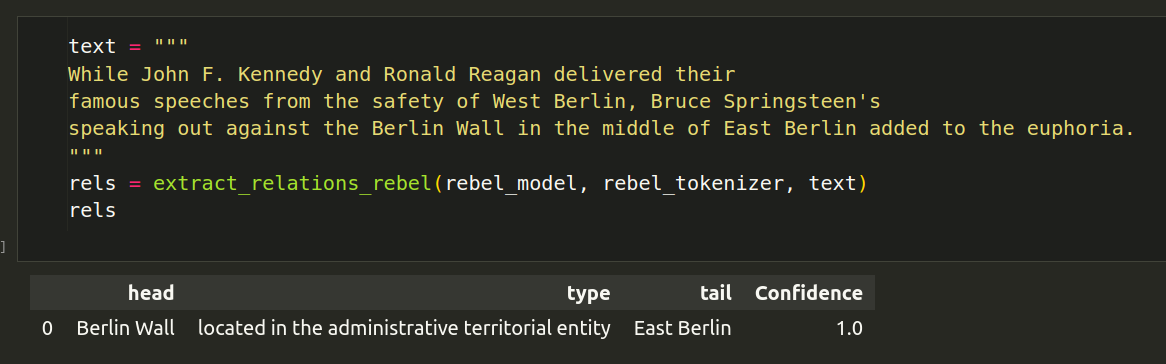
In the above example, the sentence is about Bruce Springsteen's speaking in the middle of East Berlin and not about Berlin Wall being in the middle of East Berlin. This is some unexpected behaviour.
For the discussion with the author, refer here - Extraction of non-existant relation
Validation issues
In the project description given here and as mentioned while restating the goal, our aim is to disambiguate the relation between entities that are linked from a wiki page and thus only connected via dbo:wikiPageWikiLink predicate.. When we run the pipeline on a wiki page text, it gives a list of triples. These triples don’t necessarily contain the current page/entity as the subject. So, in terms of validation, we can either remove those and only select the ones that have the current page as the subject entity, this will definitely solve our purpose.
Below is the code to fetch entities with particular predicates wrt to a given entity.
def get_wikiPageWikiLink_entities(entity, sparql_wrapper=sparql):
"""A function to fetch all entities connected to the given entity
by the dbo:wikiPageWikiLink predicate.
Args:
entity (_type_): The source entity, the wiki page we are parsing.
Example --> <http://dbpedia.org/resource/Berlin_Wall>.
sparql_wrapper : The SPARQL endpoint. Defaults to sparql.
Returns: List of entities.
"""
query = f"""
PREFIX dbo: <http://dbpedia.org/ontology/>
SELECT ?connected_entities
WHERE{{
{entity} dbo:wikiPageWikiLink ?connected_entities .
}}
"""
sparql_wrapper.setQuery(query)
sparql_wrapper.setReturnFormat(JSON)
results = sparql_wrapper.query().convert()
entities = [
r["connected_entities"]["value"] for r in results["results"]["bindings"]
]
return entities
def get_only_wikiPageWikiLink(entity, sparql_wrapper=sparql):
"""For a given entity(the current wiki page), returns all entities
that are connected with only the dbo:wikiPageWikiLink predicate and no
other predicate.
Args:
entity : The source entity, the current wiki page.
Example --> <http://dbpedia.org/resource/Berlin_Wall>.
sparql_wrapper : The SPARQL endpoint. Defaults to sparql.
Returns: List of entities.
"""
query = f"""
PREFIX dbo: <http://dbpedia.org/ontology/>
SELECT ?o
WHERE {{
{{
SELECT ?o
WHERE {{
{entity} dbo:wikiPageWikiLink ?o .
}}
}}
MINUS
{{
{entity} ?p ?o .
FILTER (?p != dbo:wikiPageWikiLink)
}}
}}
"""
sparql_wrapper.setQuery(query)
sparql_wrapper.setReturnFormat(JSON)
results = sparql_wrapper.query().convert()
return results["results"]["bindings"]
But when doing this, we may miss upon useful information regarding other entities. We need some way to keep these other triples stored or streamed somewhere so that we can still make use of them.
One way to deal with this is that we store all triples and store them in a way such that we can get all triples with a specific subject entity together, so that we can disambiguate the relationships with that entity. This is similar to the map-reduce paradigm, something like this - the mapper emits relational triples, we accumulate them my the subject as the key, and the the reducer does the disambiguation task(checking if dbo:wikiPageWikiLink exists and no other predicate exists) for all triples for a particular subject.
Scaling
This one’s probably the most important in terms of the usability of the project. We need to run our pipeline of many many wikipedia pages. In order for this to happen in a reasonable amount of time, we need to think of ways to efficiently scale this pipeline.
I was reading recently regarding streaming, message-broking etc and thought of applying this to our pipeline. Something like modelling the components in our pipeline as producers and consumers of data streams. In this way, we can process the data in transit, one component of the pipeline would not need to wait till the other components(after it) finish. This would save us a lot of time. More on this in the next blog.
Thank you!