(GSoC) Week-4 GENRE for entity linking
Hello. In this blog, I will be writing about using a text generation model to disambiguate entities, GENRE. It stands for Generative Entity Retrieval, presented in the Autoregressive Entity Retrieval paper by facebook research.
In a nutshell, GENRE uses a sequence-to-sequence approach to entity retrieval (e.g., linking), based on fine-tuned BART architecture. GENRE performs retrieval generating the unique entity name conditioned on the input text using constrained beam search to only generate valid identifiers.
What is an autoregressive approach in EL?
GENRE uses an approach where it retrieves entities by generating their unique names, from left-to-right, in an autoregressive manner(considering context). Most of the classical approaches to entity retrieval treat it as a multi-class classification problem, where the entities in the knowledge base(we can call these resources) are associated with labels. They simply use the dot product of dense embeddings of the input and the dense embeddings of the entity/resource metadata(like text in the article, description, abstract etc).
Below are some examples of situations in which GENRE can disambiguate entities(taken from paper):

The classical approaches has some disadvantages:
- Dot product can miss fine relations between entity and context.
- Large memory footprint becuase of dense embeddings for entities and metadata.
- Does not work for new entities, at least need metadata(like description to compare input vector to).
Architecture
GENRE uses a transformer based architecture, pre-trained on a language modelling objective and finetuned to generate entities. To keep a check on the validity of the generated entity name, GENRE uses constrained decoding, thus forcing generated name to be in a predefined candidate set.
Benefits of using this approach:
- Capture entity-context relation.
- Low memory footprint as parameters scale with vocab, not entities.
- New entities can be easily added, by adding them to predefined candidate set.
The figure below shows how entity wiki titles are generated:

Beam search
The seq-2-seq models basically try to predict the next word given a sequence of words, by using logits. These models generate a probability distribution over the tokens, and then decoding strategies are used to select the next token. Simplest of them is greedy search, just selects the maximum probability token. But this considers the max probability only at that step, not for the whole sentence after generation is complete. But it can miss on sentences that appear with less probability next token.
Beam search on the other hand, considers n(number of beams) most probable tokens at each steps and repeats until a predefined sequence length is reaches or a EOS token is reached. And then, the sequence with highest overall probability is chosen.
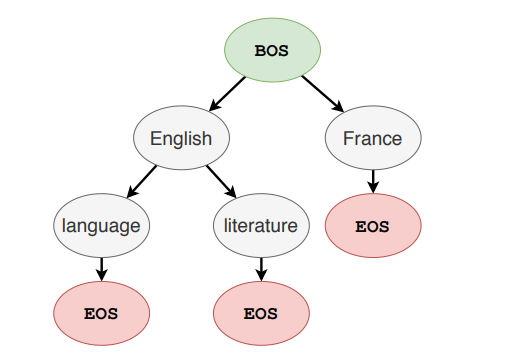
GENRE uses constrained beam search to only generate valid entity names. For this, it uses a prefix tree, in which a node is a token and its children are the allowed continuations from the prefix while traversing the tree from root to the node. This prefix tree can be called a trie. As we have the predefined entities, we can pre-compute this trie.
The figure below shows a trie where the allowed entities identifiers are ‘English language’, ‘English literature’ and ‘France’.
End-to-End entity linking
GENRE also address end-to-end EL problem. Given a document, it can return the document with entity mentions annotated with KB entity spans. At each generation step, the decoder is either generating a mention span, generating a link to a mention, or continuing from the input source.
Sample code to use GENRE for entity linking
Thank you!